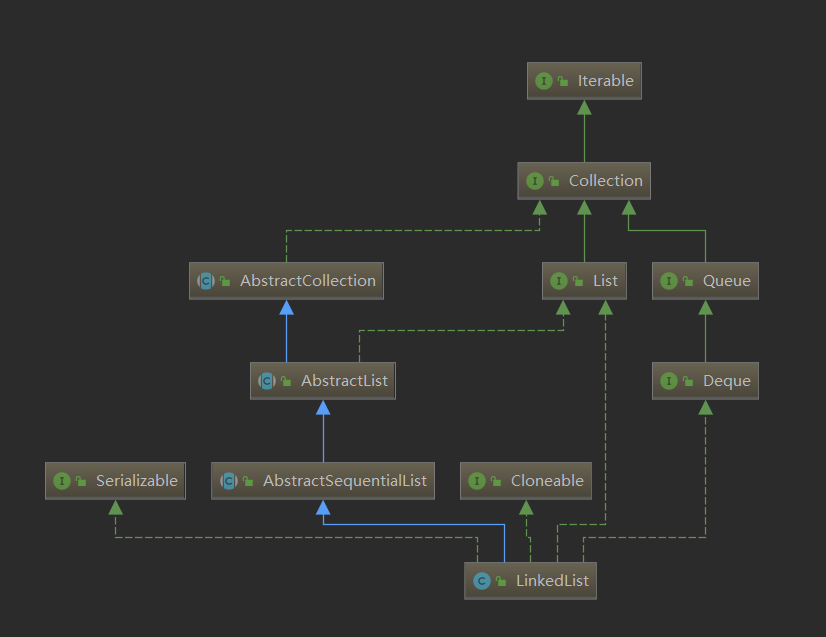
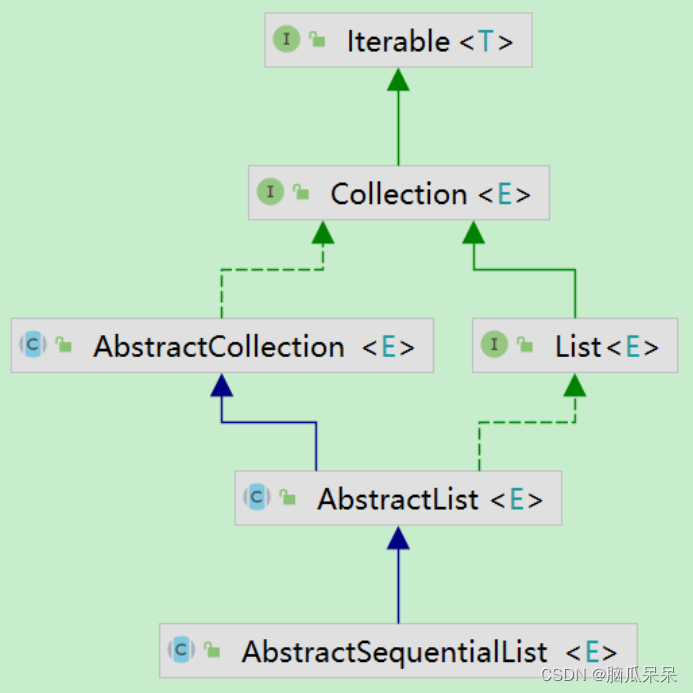
Object[] a = c.toArray(); //将集合转化为数组 intnumNew= a.length; if (numNew == 0) //如果数组长度为0,返回false returnfalse;
Node<E> pred, succ; //得到插入节点的前驱节点和后继节点 if (index == size) { //如果插入节点为尾部,前驱节点就是last,后继节点就是null succ = null; pred = last; } else { //否则,调用node获取后继节点,再获取前驱节点 succ = node(index); pred = succ.prev; }
for (Object o : a) { //遍历数据将数据插入 @SuppressWarnings("unchecked")Ee= (E) o; Node<E> newNode = newNode<>(pred, e, null); //创建新节点 if (pred == null) //如果前驱节点是null,证明新节点就是头节点 first = newNode; else pred.next = newNode; pred = newNode; //更新前驱节点为新节点 }
if (succ == null) { //如果后继节点为空,那么尾节点就是集合最后一个节点,即最后更新为pred的新节点 last = pred; } else { //否则,将后继节点与前面的节点连接起来 pred.next = succ; succ.prev = pred; }
//删除第一个元素 public E removeFirst() { final Node<E> f = first; //获取第一个元素 if (f == null) //如果为空,抛出异常 thrownewNoSuchElementException(); //没有这样的元素异常 return unlinkFirst(f); //调用unlinkFirst()方法对元素进行删除 }
private E unlinkFirst(Node<E> f) { //私有方法,只能类内调用 // assert f == first && f != null; final E element= f.item; final Node<E> next = f.next; //获取f的后继节点赋值给next f.item = null; //将f的值赋为空 f.next = null; // 依靠GC回收 first = next; //将头节点赋值为f的后继节点next if (next == null) //如果后继节点为空,那么尾节点也为空 last = null; else next.prev = null; //否则,将后继节点的前驱节点赋值为空 size--; //将链表长度减一 modCount++; //操作数加一 return element; //返回删除元素的值 }
public E removeLast() {//删除尾节点 final Node<E> l = last; if (l == null) thrownewNoSuchElementException(); return unlinkLast(l); }
public E pollLast() { //删除尾节点 final Node<E> l = last; return (l == null) ? null : unlinkLast(l); }
private E unlinkLast(Node<E> l) { //和删除头节点相似 // assert l == last && l != null; finalEelement= l.item; final Node<E> prev = l.prev; l.item = null; l.prev = null; // help GC last = prev; if (prev == null) first = null; else prev.next = null; size--; modCount++; return element; }
publicbooleanremove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { //遍历链表找到null if (x.item == null) { unlink(x); returntrue; } } } else { for (Node<E> x = first; x != null; x = x.next) { //遍历链表找到o if (o.equals(x.item)) { unlink(x); returntrue; } } } returnfalse; }
unlink(Node<E> x) { //删除一个元素x // assert x != null; finalEelement= x.item; final Node<E> next = x.next; //将节点的下一个位置赋值给next final Node<E> prev = x.prev; //将节点的上一个位置赋值给prev
if (prev == null) { //如果prev等于null,证明头节点为next first = next; } else { //否则上一个位置的后继节点为next,删除节点的前驱节点赋值为null prev.next = next; x.prev = null; }
if (next == null) { //和前面相似 last = prev; } else { next.prev = prev; x.next = null; }