
什么是Kafka?
Kafka是一个开源的分布式事件流平台,事件流就是从事件源以事件流的形式实时捕获数据的时间,持久存储这些事件流供以后检索,实时和回顾地操作、处理和响应事件流,并根据需要将事件流路由到不同的目标技术。事件流保证了数据的连续流动性和解释,以便正确的信息在正确的时间出现在正确的位置。
Kafka最初由LinkedIn开发并开源,后来称为Apache软件基金会的一个顶级项目。它被设计用于高吞吐量、持久性、分布式的数据流处理。
Kafka与其他消息队列区别
消息队列是分布式系统中重要的组件,利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,比RocketMQ、Kafka低一个数量级 | 万级,比RocketMQ、Kafka低一个数量级 | 十万级,支撑高吞吐,支持强一致性,强一致性下吞吐量稍低 | 十万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic数量对吞吐量的影响 | topic可以达到几百几千个的级别,吞吐量会有较小幅度的下降。这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic | topic从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,Kafka尽量保证topic数量不要过多,如果支撑大规模的topic,需要增加更多的机器资源 | ||
| 时效性 | 毫秒级 | 微秒级,这是RabbitMQ的一大特点,延迟性是最低的 | 毫秒级 | 毫秒级以内 |
| 可用性 | 高,基于总从架构实现高可用性 | 高,基于总从架构实现高可用性 | 非常高,分布式架构 | 非常高,Kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 经过参数优化,可以做到0丢失 | 经过参数优化,可以做到0丢失 | |
| 功能支持 | MQ领域的功能极其完备 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低 | MQ功能较为完善,分布式的,扩展性好 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
Kafka的应用场景
1、消息:Kafka更好地替换传统的消息系统,消息系统被用于各种场景,与大都数消息系统比较Kafka有更好的吞吐量内置分区、副本和故障转移,这有利于处理大规模的消息。
2、网站活动追踪:Kafka原本的使用场景是用户的活动追踪,网站的活动(网页浏览,搜索或其他用户的操作信息)发布到不同的话题中心,这些消息可实时处理实时监测,也可加载到Hadoop或者离线处理数据仓库。
3、指标:Kafka也常常用于监测数据,分布式应用程序生成的统计数据集中聚合。
4、日志聚合:许多人使用Kafka作为日志聚合解决方案的替代品。日志聚合通常从服务器中收集物理日志文件,并将它们放在中央位置进行处理。Kafka抽象出文件的细节,并将日志或时间数据更清晰地抽象为消息流。这允许更低延迟的处理并更容易支持多个数据源和分布式数据消费。
5、流处理:Kafka中消息处理一般包含多个阶段。其中原始输入数据是从Kafka主题消费的,然后汇总,丰富,或者以其他的处理方式转化为新主题。
6、事件采集:事件采集是一种应用程序的设计风格,其中状态的变化根据时间的顺序记录下来,Kafka支持这种非常大的存储日志数据的场景。
7、提交日志:Kafka可以作为一种分布式的外部日志,可帮助节点之间复制数据,并作为失败的节点来恢复数据重新同步,Kafka的日志压缩功能很好地支持这种用法。
消息队列的两种模式
1、点对点模式
消费者主动拉取数据,消息收到后清除消息。
2、发布/订阅模式
可以有多个topic主题。
消费者消费数据后,不删除数据。
每个消费者相互独立,都可以消费到数据。
区别:
点对点消费消息只能发布到一个主题,消费完成就删除消息,并且只有一个消费者。
发布/订阅模式消息可以发布到多个主题,消息一般保留七天,并且有多个消费者。
Kafka基本架构
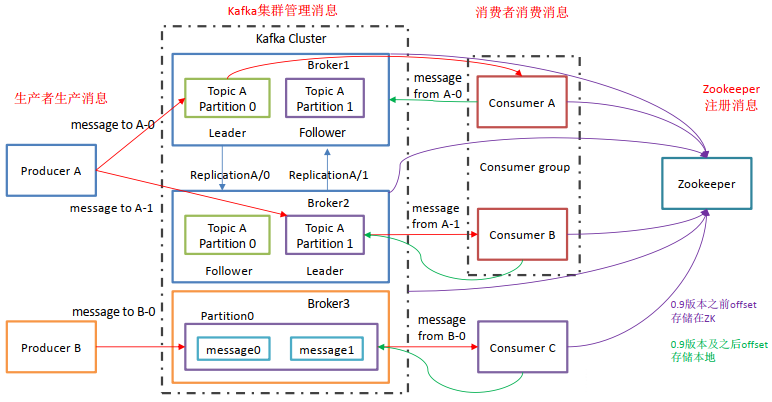
Producer:消息生产者,就是向Kafka Broker发消息的客户端。
Consumer:消息消费者,就是从Kafka Broker拉取消息的服务端。
Consumer Group:消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费。消费者组之间互不影响。所有消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组内的一个消费者所消费。
Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic。
Partition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序队列。分区有序,不能保证全局有序,如果要保证全局有序,则只能使用一个Partition。
Replication:副本,为了保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常地工作,Kafka提供了副本机制,一个Topic的每个分区有若干副本,一个Leader和多个Follower。
Leader:每个分区多个副本的主角色,生产者发送数据的对象以及消费者消费数据的对象都是Leader。
Follower:每个分区多个副本的从角色,实时地从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。



