
一、SQL优化
(一)插入数据
批量插入
多次插入每一次insert都要与数据库建立连接。
1 | INSERT INTO 表名 VALUES (),(),(); |

一次插入数据不宜过多,不要超过1000条。
手动提交事务
1 | START TRANSACTION; |
主键顺序插入
* 编辑* 主键顺序插入效率高于乱序插入。
编辑* 主键顺序插入效率高于乱序插入。
大批量插入数据
如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令进行插入。
 编辑
编辑
1 | --查看开关是否开启 |
(二)主键优化
数据组织方式:在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表。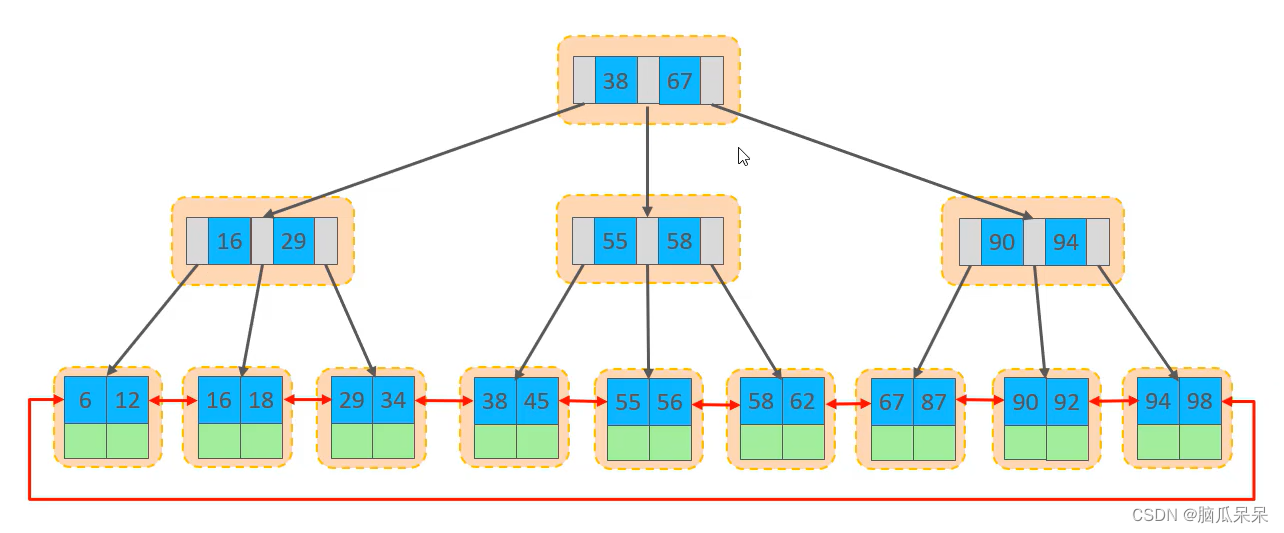 编辑
编辑
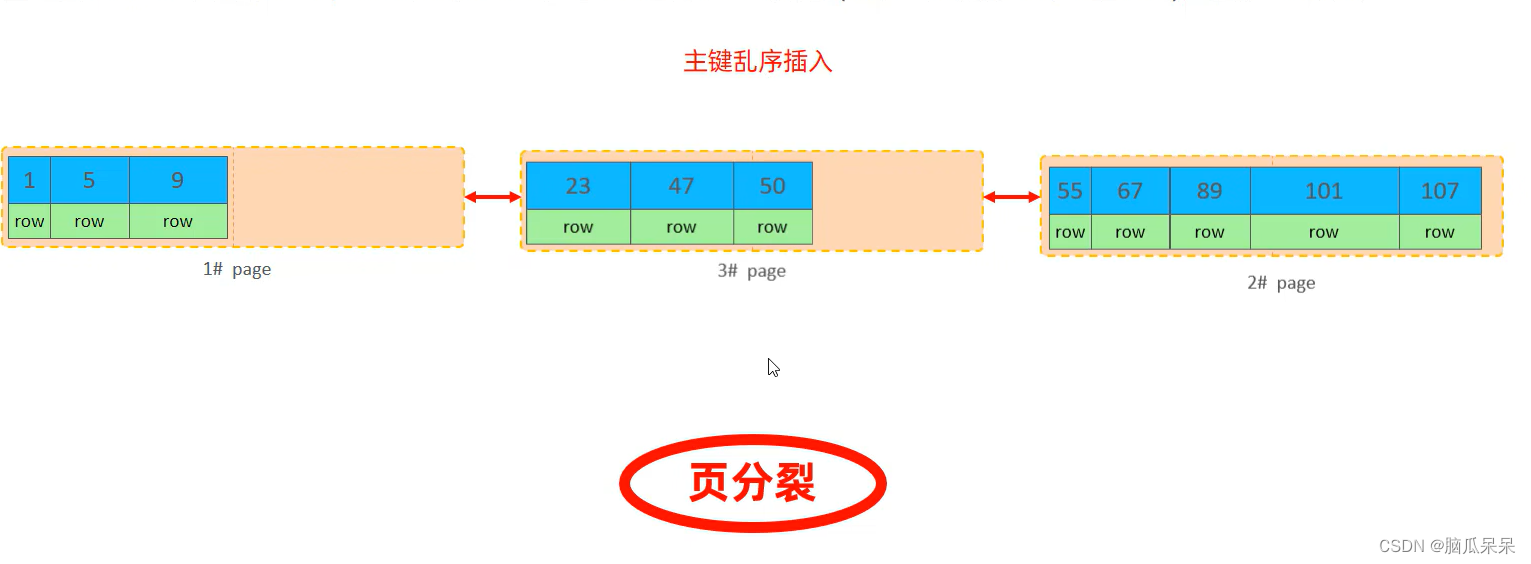
页分裂:页可以为空,也可以填充一半,也可以填充到100%。每个页包含了2-N行数据(如果一行数据足够大,会行溢出),根据主键排序。主键乱序插入时可能会发生。
**** 编辑**页合并:**当删除一行记录时,实际上记录并没有被物理删除,只是被标记(flaged)为删除并且它的空间变的允许被其他记录声明使用。
编辑**页合并:**当删除一行记录时,实际上记录并没有被物理删除,只是被标记(flaged)为删除并且它的空间变的允许被其他记录声明使用。
当页中删除的记录达到MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个合并以优化空间使用。
MERGE_THRESHOLD:合并页的阈值,可以自己设置,在创建表或者创建索引时指定,在创建表和创建索引的时候可以自己指定。
主键设计原则:
满足业务需求的情况下,尽量降低主键的长度。
插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键。
尽量不要使用UUID做主键或者是其他自然主键,如身份证号,无序,长度也较长。
业务操作时,避免对主键的修改。
(三)order by优化
Using filesort:通过表的索引或者全表扫描,读取满足条件的数据行,然后再排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的都叫FileSort排序。
Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为using index,不需要额外排序,操作效率高。
Backward index scan:反向扫描索引。
1 | --根据字段1,字段进行一个降序,一个升序 |
优化:
根据排序字段创建合适的索引,多字段排序时,也遵循最左前缀法则。
尽量使用覆盖索引。
多字段排序时,一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。
如果不可避免的出现filesort,大数据排序时,可以适当增大排序缓冲区的大小sort_buffer_size(默认256k)。
1 | SHOW VARIABLES LIKE 'sort_buffer_size'; |
(四)group by优化
Using temporary:用到了临时表。
分组操作时,建立适当索引来提高效率。
分组操作时,索引的使用也是满足最左前缀原则的。
(五)limit优化
一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查询的方法优化。
1 | EXPLAIN SELECT a.* FROM 表1 a,(SELECT id FROM 表2 ORDER BY id LIMIT 开始,数量) b WHERE a.id=b.id; |
(六)count优化
在MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高,前提是后面没有where条件。
InnoDB引擎在执行count(*)时,需要把数据一行行地从引擎里面读出来,然后累积计数。
优化思路:没有特别好的优化方案,可以自己计数。
用法:count(*)、count(主键)、count(字段)、count(1)
count(主键):InnoDB引擎会遍历整张表,把每一行的主键id值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键值不可能为null)。
count(字段):InnoDB遍历整张表把每一行的字段值都取出来,返回给服务层。如果有not null约束,直接按行进行累加;如果没有not null约束,服务层判断是否为null,不为null,计数累加。
count(1):InnoDB引擎会遍历整张表,但不取值。服务层对于返回的每一行,都放一个数字“1”进去,直接按行进行累加。
count(*):InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。
性能:count(*)~count(1)>count(主键)>count(字段),尽量使用count( *)。
(七)update优化
执行update语句的注意事项:
在InnoDB的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则会从行锁升级为表锁。
二、视图/存储过程/触发器
(一)视图
视图是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。
视图不保存数据,只保存了SQL的逻辑。我们在创建视图时,主要的工作就在创建这条SQL查询语句上。
创建
1 | CREATE [OR REPLACE] VIEW 视图名称[(列表列名)] AS SELECT语句 [WITH [CASCADED|LOCAL] CHECK OPTION]; |
封装的就是select查询的数据。
WITH CASCADED CHECK OPTION:防止视图插入的数据不符合创建视图时的条件。
视图的检查选项:当使用WITH CHECK自居创建视图时,MySQL会通过视图检查正在更改的每个行,以使其符合视图的定义。MySQL允许基于另一个视图创建视图,他还会检查依赖视图中的规则以保持一致性。为了确定检查的范围,MySQL提供了两个选项:CASCADED和LOCAL,默认值是LOCAL。
CASCADED:
 编辑
编辑
LOCAL:
查询
1 | --查看创建视图语句 |
视图是一种虚拟的表,可以像操作表一样操作视图。
修改
1 | CREATE OR REPLACE VIEW 视图名称{(列名列表)} AS SELECT语句 [WITH [CASCADED|LOCAL] CHECK OPTION]; |
CREATE OR REPLACE:创建或替换。
删除
1 | DROP VIEW [IF EXISTS] 视图名称 [,视图名称]...; |
IF EXISTS:判断是否存在。
视图的更新:
要使视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系。如果视图包含一下任何一项,则该视图不可更新:
1、聚合函数或窗口函数(SUM()、MIN()、MAX()、COUNT()等)
2、DISTINCT
3、GROUP BY
4、HAVING
5、UNION或者UNION ALL
作用:
操作简单:视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使得用户不必为以后的操作每次指定全部的条件。
安全:数据库可以授权,但不能授权到数据库特定的行和特定的列上。通过视图用户只能查询和修改他们能见到的数据。
数据独立:视图可以帮助用户屏蔽表真实结构变化带来的影响。
(二)存储过程
存储过程是事先经过编译并存储在数据库中的一段SQL语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。
存储过程思想上很简单,就是数据库SQL语言层面的代码封装与重用。
创建
1 | CREATE PROCEDURE 存储过程名称([参数列表]) |
调用
1 | CALL 名称([参数]); |
查看
1 | --查询指定数据库的存储过程及状态信息 |
删除
1 | DROP PROCEDURE [IF EXISTS] 存储过程名称; |
注意:在命令行执行sql时,一旦遇到分号,就认为SQL语句结束。所以在命令行中,执行创建存储过程的SQL时,需要通过delimiter关键字指定SQL语句的结束符。
系统变量
系统变量是MySQL服务器提供,不是用户定义的,属于服务器层面。分为全局变量(GLOBAL)、会话变量(SESSION)。
全局变量:针对所有会话有效。
会话变量:仅在当前会话内有效。
查看系统变量
1 | --查看所有系统变量(默认session级别) |
设置系统变量值
1 | SET [SESSION|GLOBAL] 系统变量名=值; |
如果没有指定SESSION|GLOBAL,默认是SESSION,会话变量。
MySQL服务重新启动之后,所设置的全局参数会失效,要想不失效,可以再/etc/my.cnf中配置。
用户自定义变量
用户定义变量是用户根据需要自己定义的变量,用户变量不用提前声明,在用的时候直接用”@变量名“使用就可以。其作用域为当前连接。
赋值
1 | SET @var_name=expr[,@var_name=expr]...; |
使用
1 | SELECT @var_name; |
用户定义的变量无需对其进行声明或者初始化,只不过获取到的值为NULL。
局部变量
局部变量是根据需要定义的在局部生效的变量,访问之前,需要DECLARE声明。可用作存储过程内的局部变量和输入参数,局部变量的范围是在其内声明的BEGIN···END块。
声明
1 | DECLARE 变量名 变量类型[DEFAULZT...]; |
赋值
1 | SET 变量名=值; |
if条件判断
1 | IF 条件1 THEN |
case选择
1 | --语法一 |
while循环
满足条件进行循环,先判断条件。
1 | WHILE 条件 DO |
repeat循环
满足条件推出循环,先执行一次逻辑,再判断条件。
1 | REPEAT |
loop循环
如果不在SQL逻辑中增加退出循环的语句,就是死循环。loop可以配合以下两个语句使用:
(1)LEAVE:配合循环使用,退出循环。
(2)ITERATE:跳过剩下的语句,直接进入下一次循环。
1 | [begin_label:]LOOP |
存储过程参数
| 类型 | 含义 | 备注 |
|---|---|---|
| IN | 该类参数作为输入,也就是需要调用时传入值 | 默认 |
| OUT | 该类参数作为输出,也就是该参数可以作为返回值 | |
| INOUT | 既可以作为输入参数,也可以作为输出参数 |
用法
1 | CTEATE PROCEDURE 存储过程名称([IN/OUT/INOUT 参数名 参数类型]) |
游标
游标时用来存储查询结果集的数据类型,在存储过程和函数中可以使用游标对结构及进行循环的处理。游标的使用包括游标的声明、OPEN、FETCH和CLOSE,其语法分别如下。

编辑
声明游标
1 | DECLARE 游标 CURSOR FOR 查询语句; |
打开游标
1 | OPEN 游标名称; |
获取游标记录
1 | FETCH 游标名称 INTO 变量[,变量]; |
条件处理程****序
条件处理程序可以用来定义在流程控制结构执行过程中遇到问题时相应的处理步骤。具体语法为:
1 | DECLARE handler_action HANDLER FOR condition_value [,condition_value]... statement; |
handler_action:
CONTINUE:继续执行当前程序。
EXIT:终止执行当前程序。
condition_value:
SQLSTATE sqlstate_value:状态码,如02000。
SQLWARNING:所有以01开头的SQLSTATE代码的简写。
NOT FOUND:所有以02开头的SQLSTATE代码的简写。
SQLEXCEPTION:所有没有被SQLWARNING或NOT FOUND捕获的SQL STATE代码的简写。
(三)存储函数
存储函数是由返回值的存储过程,存储函数的参数只能是IN类型,具体语法:
1 | CREATE FUNCTION 存储函数名称([参数列表]) |
characteristic说明:
DETERMINSTIC:相同的输入参数总是产生相同的结果。
NO SQL:不包含SQL语句。
READS SQL DATA:包含读取数据的语句,但不包含写入数据的语句。
(四)触发器
触发器是与表有关的数据库对象,在insert/update/delete之前或者之后,触发并执行触发器中定义的SQL语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性,日志记录,数据校验等操作。
使用别名OLD和NEW来引用触发器中发生变化的记录内容,这与其他数据库是相似的。现在触发器还只支持行级触发,不支持语句级触发。
*** 编辑*创建
编辑*创建
1 | CREATE TRIGGER trigger_name |
查看
1 | SHOW TRIGGERS; |
删除
1 | DROP TRIGGER [schema_name.]trigger_name; |



